
Schritt 1 Daten einlesen und verschlanken
Bevor ich mit dem Einlesen, damit meine ich ein dataframe zu erstellen, beginne, muss ich die Daten aus der Kundendatenbank extrahieren. Da dies eine DBF -Datenbank ist, kann ich die Daten nicht einfach einlesen. Hierfür werde ich diese erst in ein passendes Format bringen. Dazu importiere ich mir die folgenden Pakte, wobei für das Umwandeln das Paket dbfread entscheident ist.
import pandas as pd
import numpy as np
import datetime as dt
from dbfread import DBF
import matplotlib.pyplot as pltMit
„dbf = DBF(„data/STATIST.DBF“)“
lese ich die Daten über den Pfad ein. Erst danach kann ich ein dataframe erstellen.
Dies geschieht durch
df = pd.DataFrame(dbf).
Um mit ein Bild für den Umfang des dataframe zu machen, nutze ich die Funktion
df.info()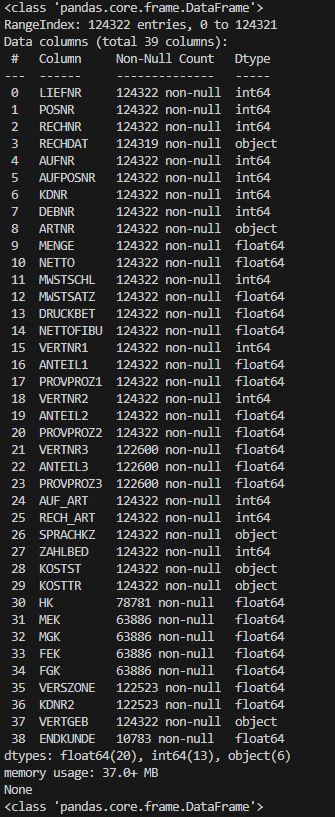
Da dies ein recht großes dataframe( 38 Spalten mit 124.322 Einträgen) ist, habe ich mir überlegt ein kleines daraus zumachen. Hierbei nutze ich für diesen Schritt nur die Spalten auf die es für mich ankommt.
Mit der Funktion
df_2 = df[["RECHDAT", "KDNR", "ARTNR", "MENGE", "NETTO","VERTNR1"]].copy()
erstelle ich mir das schlanke dataframe „df_2“. Aus dem ursprünglichem dataframe habe ich folgende Spalten mitgenommen.
- RECHDAT –> Datum der Rechnung
- KDNR –> Kundennummer
- ARTNR –> Artikelnummer
- MENGE –> verkaufte Menge
- NETTO –> Nettoumsatz
- VERTRETNR1 –> Der Indikatior für den betreffenden Sales Mitarbeiter
Nun sind die Daten eingelesen und verschlankt, aber ich muss diese noch bereinigen.
Schritt 2 – Datenbereinigung
Einge Spalten beinhalten Werte, welche ich als sogenannte Integer benötige. Kurz Integer sind Zahlen. Ich merke gerade, dass ich auch mal einen post über die Datentypen machen muss.
Gut ich benötige die Spalten „NETTO“ und „MENGE“ als Integer. Dies lässt wie folgt umsetzen:
df_2["NETTO"]= df_2["NETTO"].astype(int)
df_2["MENGE"]= df_2["MENGE"].astype(int)
Die Spalte „RECHDAT“ benötige ich im Format date.
df_2["RECHDAT"]= pd.to_datetime(df_2["RECHDAT"])
Leider gibt es Datensätze, welche in den Mengen und in den Umsätzen negative Werte ausweisen. Da dies sog. Gutschriften sind, bereinige ich Daten auch um diese in dem ich nur Datensätze betrachte in dem die Menge und der Umsatz größer Null ist.
df_3 = df_2[(df_2["MENGE"]>0)& (df_2["NETTO"]>0)]
Nun habe habe ich die Daten bereingt, das heißt wir können starten.
Schritt 3- Das R ermitteln
Zur Erinnerung in der RFM-Anlayse steht das R für recency(Aktualität). Um diese ermitteln zukönnen, benötige ich einen Zeitpunkt, von dem ich ausgehen kann. Hierbei muss dieser Zeitpunkt der spätest mögliche Tag sind. Ich habe mich hier für den 9.11.2023 entschieden und ihn wie folgt definiert:
last_date = dt.datetime(2023,11,9)
Der nächste Schritt ist entscheidet. Ich gruppiere die Daten nach der Kundennummer und ermittle gleichzeitig wie viel Tage es vom 09.11.2023 her sind, als der Kunde das letzte Mal bestellte. Hier geht es nur um die Anzahl der Tage, nicht um die bestellte Menge und den damit einhergehenden Umsatz.
Diese Berechnung mache ich mit:
rfm = df_3.groupby("KDNR").agg({"RECHDAT":lambda x: last_date-x.max()})
Lasst mich diese Zeile erläutern:
- df_3.groupby(„KDNR“) –> hier werden die Daten auf die Kundennummer gruppiert. Dies hat den Vorteil, dass jede Kundennummer dann nur einmal vorhanden ist
- agg({„RECHDAT“… –> sorgt dafür, dass die Berechnung nach den Rechnungsdatum erfolgt
- lambda x: last_date-x.max()}) –> hier erfolgt die Berechnung der Anzahl der Tage, wie lange die letze Bestellung her ist.
Da jetzt eine sog. pivot-Tabelle entstanden ist, führe ich diese wieder in ein Dataframe zurück.
rfm["KDNR"] = rfm.index
Nun habe ich ein dataframe „rfm“. Bevor ich mir das einmal graphisch anschaue, prüfe ich wieviele Kundennummern es gibt, welche jemals bestellt haben. Dies prüfe ich durch:
print(df_3["KDNR"].nunique())
Es sind genau 736 Kunden. Das heißt 736 Kunden haben jemals etwas bei diesem Unternehmen bestellt und gekauft. Diese 736 sind zentral für alle weiteren Ausführungen.
Schritt 3 – Der Plot von R
Um ein Gefühl für die Verteilung zu erhalten, möchte ich mir diese Daten einmal in einem Histogram plotten. Dafür definiere ich mir Balkenbreiten von 250 Tage.
bins = range(0,6000,250)Und mit
rfm.hist(bins=bins)
plt.show()plotte ich mir das Histogram. È volia…
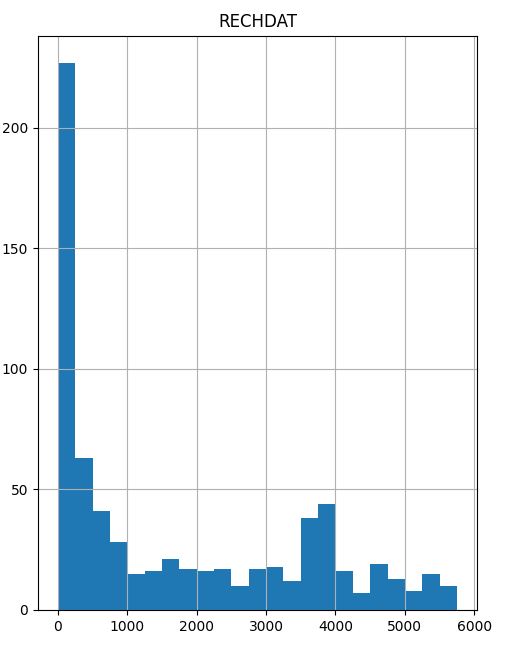
Oh… eine sehr interessante Verteilung. Folgendes lässt sich hier ablesen:
- 250 Kunden oder 33,96% der Kunden haben den letzten 250 Tagen bestellt
- 310 Kunden oder 42,11 % der Kunden haben in den letzten 500 Tagen bestellt
- 57,89% der Kunden haben in den letzten 500 Tagen nicht mehr bestellt
Gerade der letzte Punkt ist eine sehr interessante Erkenntnis, auch weil ich weiß, dass das betrachete Unternehmen sehr auf wiederkehrende Geschäfte mit ihren Kunden abstellt.
Aber lasst uns mit dem F weitermachen…
Dann aber nächstes Mal.
Der Fux