Im letzten Post habe ich am Ende geschrieben, dass das dort gezeigte Ergebnis einen sehr geringen Aussagewert hat.
Ich zeig Euch mal warum:
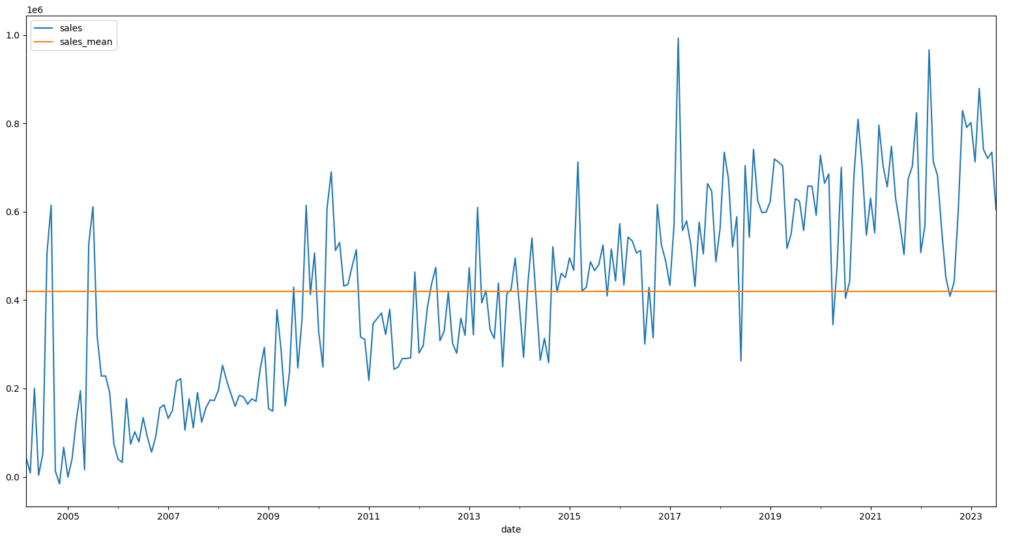
Die horizontale Linie beschreibt den Mittelwert über die gesamte Zeitreihe. Die blaue die Werte der Zeitreihe. Was erkenne ich hier?
Nicht viel. Es gibt Werte die über und unter dem Mittelwert liegen. Eine Entwicklung anhand des Mittelwerts ist nicht erkennbar.
Betrachten wir die Sache doch einmal auf Jahresebene.
Der Mittelwert – auf Jahresebene
Bevor wir dies als Grafik plotten können, müssen die Daten angepasst werden. Zuerst werden wie gewohnt die benötigten Bibliotheken importiert. Dies sind pandas, numpy und matplotlib.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Weiterhin müssen wir die jeweiligen Jahreszahlen aus den Daten extrahieren. Dies mache ich wie folgt:
data["date"] = pd.to_datetime(data["date"])
Damit wird die Spalte „date“ in ein Datums-Format umgewandelt.
data["year"] =data["date"].dt.year
Hiermit wird eine Spalte „year“ ins dataframe eingefügt, welche den Name „Year“ hat. Mit der folgenden Zeile erstellen wir uns ein neues Dataframe, welches die Mittelwerte auf Jahresebene speichert.
data_2 = data.groupby("year").mean().reset_index()- data_2 ist der Name des erstellten dataframe
- .groupby(„year“) sorgt dafür, dass die Daten nach den vorhandenen Jahreszahlen gruppiert werden
- .mean() berechnet den Mittelwert
- .reset_index() sorgt für eine ordentliche Struktur des dataframes
Im Codeblock sieht das wie folgt aus:
Leider müssen wir die Daten noch ein wenig bearbeiten, bevor wie sauber plotten können.
Der Plot – Vorbereitungen und Darstellung
Um beide dataframes in einer Grafik zu plotten, füge ich die daframe „data“ & „data_2“ zusammen. Dies mache ich über die Methode „pd.merge“. Wie die funktioniert, schreibe ich in einem separaten Post.
Bevor ich sinnvoll weitermachen kann, benenne ich die Spalte „sales“ in „data_2“ in „mean_year“ um. „mean_year“ deshalb, weil ich ja den Mittelwert pro Jahr zeigen möchte. Dies geht über die Methode „.rename“.
data_2 =data_2.rename(columns={"sales":"mean_year"})Nun „merge“ ich die dataframes mit:
data_3 = pd.merge(data, data_2, on=["year"])Das Ergebnis von dem Plot sieht so aus:
So, jetzt sind sämtliche Vorbereitungen für den nächsten Plot abschlossen. Wir können uns dies nun wie folgt plotten lassen:
data_3.plot(x="date",y=["sales","mean_year", mean_x])
plt.show()Zur Erklärung:
- .plot ist die Methode, welche das Plotten initialisiert
- x=“data“ gibt an, dass auf der x-Achse die Spalte „date“ abgetragen wird
- y=[„sales“, „mean_year“, mean_x] gibt an, dass auf der y- Achse die Spalten „sale“, mean_x und „mean_year“ abgetragen werden
- plt.show() sorgt dafür, dass die Grafik auch ausgeworfen wird.
Und so sieht die Grafik nun aus
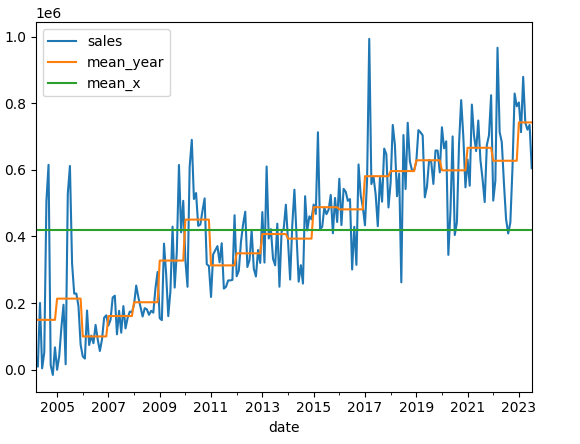
Ihr seht, dass „mean_x“ den Mittelwert über den gesamten Zeitraum aus dem Teil 1 darstellt.
„mean_year“ hingegen beschreibt nun die Mittelwerte in den jeweiligen Jahren. Dies ist schon allein vom Bauchgefühl her besser zu verstehen, als jedes Jahr den identischen Sales-Wert anzunehmen.
Des Weiteren lässt sich hier auch ein Trend erkennen, welcher im „mean_x“ nicht zu erkennen ist. Bei „mean_x“ kann ich leicht in die Annahme verfallen, dass das betreffende Unternehmen kein Wachstum aufweist und somit kaum zukunftsfähig ist. Mit „mean_year“ hingegen erkenne ich, dass es „gute“ und „nicht so gute“ Jahre gab.
Fazit
Bereits beim Mittelwert, dem zentralen und recht simplen Konzept der Statistik, muss vorab sehr genau überlegt werden, wie die Daten beschaffen sind und welche Schlüsse sich wie ziehen lassen können.
Wir sind noch nicht am Ende der Thematik angelangt. Dazu dann im nächsten Post.
Der gesamte Codeblock sieht so aus:
Viel Spass beim rumprobieren.
Euer fux